Being able to find anomalies in software license logs can help you as a software vendor to detect whenever your customers experience problems (for example, with license verifications) or to detect other types of abnormal behaviour (for example, fraudulent usage).
As the amount of data increases, detecting anomalies becomes time-consuming and, in some cases, unfeasible.
To help you to find anomalies, we have released a new dashboard that will automatically let you know of any behaviour that does not conform to the norm.
How it works
The anomaly detection module works by learning the distribution of your historical data. Any group of samples that does not conform to the norm will be classified as an anomaly.
Under the hood, an autoencoder-based neural network is used (displayed below), where the goal is to train an identity function. Since there is a bottleneck layer in the middle, it forces the network to find a compressed representation of your data. As a result, it will succeed to find such representation for most of the samples. Those samples where the network struggles to find a compressed representation are classed as anomalies.
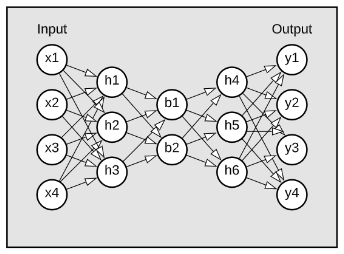
A sample can be classified as an anomaly either by its reconstruction loss (anomalies will have a higher reconstruction loss than normal samples) or by using the low-dimensional representation (the bottleneck layer) in a different method (for example, in a clustering method). In the first case, the challenge is to pick the right method to decide the decision boundary and in the latter to pick a clustering method that will be able to differentiate between normal samples and anomalies. You can read more about how it works in the following article.
Getting started
The anomaly detection module is can be accessed on the following page. It is continuously being updated, so if you notice anything or have any feedback, please reach out to us at [email protected].